Di artikel kali ini saya akan berbagi sedikit tips bagaimana mengubah laptop atau PC yang kita punya, menjadi mesin AI yang canggih — supaya kita bisa memanfaatkan AI ini sepuasnya, sebebasnya, tanpa bayar, dan full bisa kita kontrol secara penuh — karena kita akan setup AI Model apapun yang kita suka, langsung kedalam PC atau laptop yang kita punya.
Kelebihan Install AI Model di Laptop
Ada beberapa kelebihan menginstall AI Model langsung ke laptop / pc yang kita punya, dibandingkan dengan menggunakan layanan-layanan online seperti ChatGPT, Gemini, atau yang lainnya.
Pertama, kita bebas memilih model AI apa yang kita suka. Kita bisa install model AI yang tidak disensor dan tidak bias, bisa juga memilih sendiri LLM (Large Language Model) yang teroptimasi untuk keperluan tertentu, seperti buat coding, nulis, dsb.
Tentu disini AI model yang kita install merupakan AI model yang open source ya, tapi jangan salah..LLM Open Source ini perkembangannya sangat pesat! Seperti Meta, perusahaan dibalik facebook, yang baru saja ngerilis LLaMa 3. Dari hasil benchmarknya, LLaMa 3 ini nggak kalah dengan Google Gemini Pro 1.5 dan Claude 3 Sonnet untuk versi parameter 70B. Untuk versi kecilnya dengan 8B parameter, kemampuannya bahkan diatas banyak LLM Open Source lainnya. Saya sendiri sudah coba dan hasilnya memang mantap.
Kedua, data dan privasi kita jauh lebih terjaga karena semua chat, pertanyaan, ataupun jawaban dari AI nya tersimpan di local komputer kita. Gak ada pihak lain yang menyimpan percakapan kita, menggunakannya untuk data training, dsb. Jadi kalo kita pake AI untuk hal-hal yang sifatnya rahasia atau melibatkan data-data penting, AI lokal ini jauh lebih aman.
Ketiga, tentu kita bebas pake semaunya, sepuasnya, gak perlu bayar per sekian token atau bayar per bulan. Kita juga bebas pake kapanpun kita mau, nggak tergantung dengan layanan AI yang kadang servernya downtime, aksesnya lagi penuh, atau terjebak dengan perubahan-perubahan harga dan ketentuan layanannya. Karena AI lokal benar-benar dijalankan langsung dari laptop kita dan bahkan bisa kita akses secara offline.
Keempat, kita bisa lebih bebas melakukan custom ke AI model nya dengan kemampuan tertentu untuk membantu kita melakukan pekerjaan yang kita mau.
Cara Install LLM Open Source di Laptop / PC
Ada banyak cara untuk install AI model di laptop atau PC kita sendiri, tapi disini saya bagikan cara yang paling simple dan paling mudah untuk pemula — jadi teman2 bisa langsung mempraktekkan tanpa harus diribetkan dengan terminal command atau hal-hal yang terlalu teknis lainnya.
Pertama yang kita perlukan adalah laptop atau desktop, mau itu Windows, Mac, atau Linux, bebas. Disini specs nya semakin tinggi semakin bagus, terutama RAM dan GPU nya. Karena semakin besar kapasitas RAM atau VRAM GPU nya, maka kita bisa jalankan AI model yang parameternya lebih besar dengan quantization bit yang lebih besar, dengan kualitas output yang lebih baik.
Laptop atau desktop dengan 8GB RAM udah cukup oke untuk menjalankan beberapa AI model yang kecil dan ringan. Tapi 16GB RAM lebih mantap lagi karena bisa menjalankan lebih banyak pilihan AI model dengan parameter yang lebih besar. Tanpa discrete GPU tetap bisa menjalankan AI model — karena bisa dijalankan melalui RAM, tapi kalo ada discrete GPU apalagi dengan VRAM yang besar, performanya akan jauh lebih baik.
Kalo udah siap, langsung aja kita mulai.
Pertama kita install dulu aplikasi LM Studio. Temen2 bisa download di LMStudio.ai. Setelah itu tinggal install aja.
Begitu dibuka bakal muncul tampilan Home yang juga berisi highlight beberapa AI model yang populer seperti Llama 3 8B Instruct yang baru dirilis oleh Meta. Ada keterangan juga kalo LLM ini butuh 8GB RAM atau lebih. Ada juga Google Gemma dengan 2B parameter yang cukup ringan untuk dijalankan di laptop atau desktop dengan RAM 8GB atau kurang. Serta masih ada beberapa pilihan lainnya.
Nah kita juga bisa mencari dan memilih sendiri AI model yang kita mau. Tinggal search aja di kolom pencarian, dan nakal disuguhi beberapa sumber LLM Open Source dari Hugging Face. Kita bisa sort berdasarkan like atau download untuk memudahkan memilih mana yang paling populer. Untuk penjelasan AI Modelnya bisa kita baca melalui Readme atau tinggal klik aja tombol Open Model Card.
Tips Memilih AI Model yang Tepat
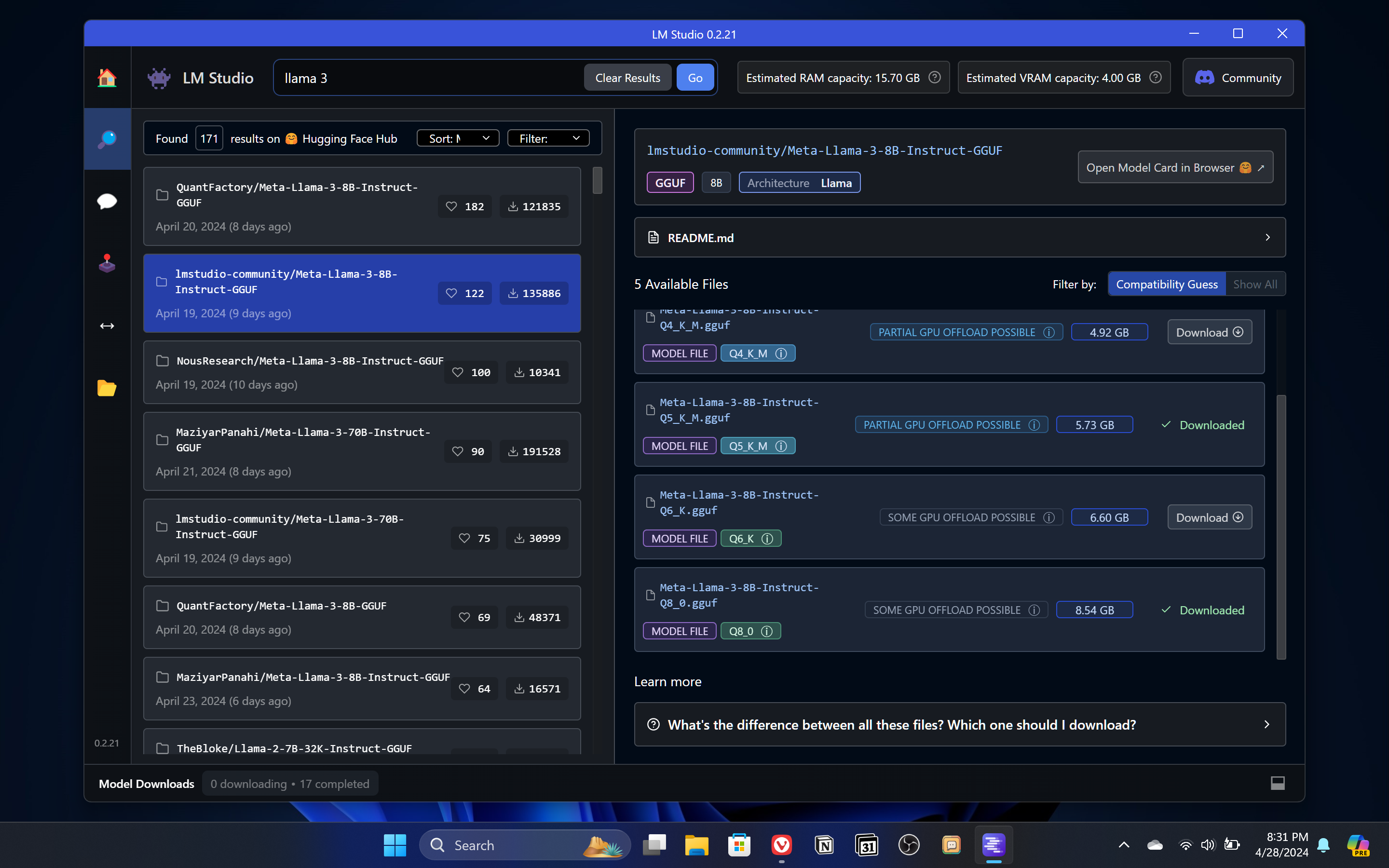
Dalam memilih AI model yang tepat buat kita, ada beberapa hal yang perlu diperhatikan.
Pertama adalah besarnya parameter, kayak 8B artinya ada 8 billion atau 8 milyar parameter, yang artinya ada 8 milyar variabel yang dipelajari oleh AI ini saat training untuk membuatnya lebih akurat dalam memahami konteks dan memprediksi jawaban. Tentu semakin besar parameternya semakin bagus, karena prediksi AI nya juga semakin akurat. Seperti LlaMa 3 70Billion Parameter jelas lebih bagus outputnya daripada yang varian 8B. Tapi karena parameternya jauh lebih besar — maka file size AI modelnya pun lebih besar dan butuh resource komputer yang lebih besar juga. Misalnya disini LM studio memprediksi LLama 3 70B parameter ini terlalu besar untuk laptop saya. Jadi saya akan download versi AI model yang lebih kecil yaitu LLAMA 3 dengan 8B parameter.
Kedua, disini terlihat ada beberapa pilihan yang bisa didownload. Misalnya ada yang Q3, Q4, Q5, Q6, sampai Q8. Q ini adalah quantization, semacam kompresi dari floating point 32-bit ke 3 bit kalo yang Q3, atau 4-bit untuk yang Q4 dst. Semakin kecil bit nya, maka ukuran file nya juga semakin kecil, AI modelnya juga semakin ringan, tapi akurasi dan kualitas output nya juga semakin kurang. Saran saya sih, untuk AI model apapun jangan download yang dibawah Q4. Karena hasil outputnya terasa kurang. Q5 lebih recommended karena seimbang antara performa dan kualitas output. Kalo laptop nya kuat, download yang Q8 juga boleh karen, hasil outputnya lebih akurat dan lebih baik — meskipun secara performa juga lebih berat dan butuh resource yang lebih besar. Disini saya bakal download yang Q8.
Ketiga, disini ada detail offload GPU nya. Full GPU Offload Possible artinya AI model bisa dijalankan sepenuhnya dari VRAM GPU dengan performa yang paling kencang dan optimal. Partial GPU offload possible atau Some GPU Offload Possible artinya sebagian komponen AI bisa di running dari VRAM GPU, memberikan performa yang sedikit lebih baik daripada sekedar dijalankan dari RAM. Dan ada juga yang Likely to large for this Machine, yang artinya LLM terlalu besar dan terlalu berat, sebaiknya pilih varian lain dengan parameter atau quantization lebih kecil.
Setelah menemukan AI yang cocok tinggal download aja. Disini kita bakal download beberapa AI model lain seperti Dolphin LLaMa 3 yang merupakan varian uncensored dari LLaMa 3, jadi kalo di chatGPT atau di layanan AI lain biasa gak mau ngasih jawaban untuk pertanyaan2 tertentu, kalo pake varian dolphin ini bakal dijawab semua. Gak ada sensor, gak ada penolakan, atau nasehat2 etik. Kita juga bakal download Mistral, salah satu AI model favorit saya yang jawabannya juga bagus, terutama untuk asisten brainstorming. Terus untuk asisten coding, kita bakal download Codellama 7B Parameter yang memang teroptimasi untuk aktivitas coding.
Buat temen2 yang laptopnya punya specs pas-pasan, bisa download beberapa AI model yang kecil dan ringan seperti Gemma dari Google yang ngebut buat laptop dengan specs pas-pasan. Gemma 2B dengan Q4 aja cuman 1.5GB. Untuk yang Q8 juga cuman 2.67GB. Ringan banget. Ada juga Phi-3 Mini dari Microsoft yang varian Q4 nya cuman 2.32GB.
Semua proses download ditampilkan dibawah, kita tinggal nunggu aja sampai prosesnya selesai. Dan semua model yang sudah didownload bisa kita lihat di folder MyModel. Total model dan total storage juga ditampilkan dan kita bisa hapus juga AI model yang udah gak kita pake lagi.
Menjalankan Local LLM Langsung dari Laptop
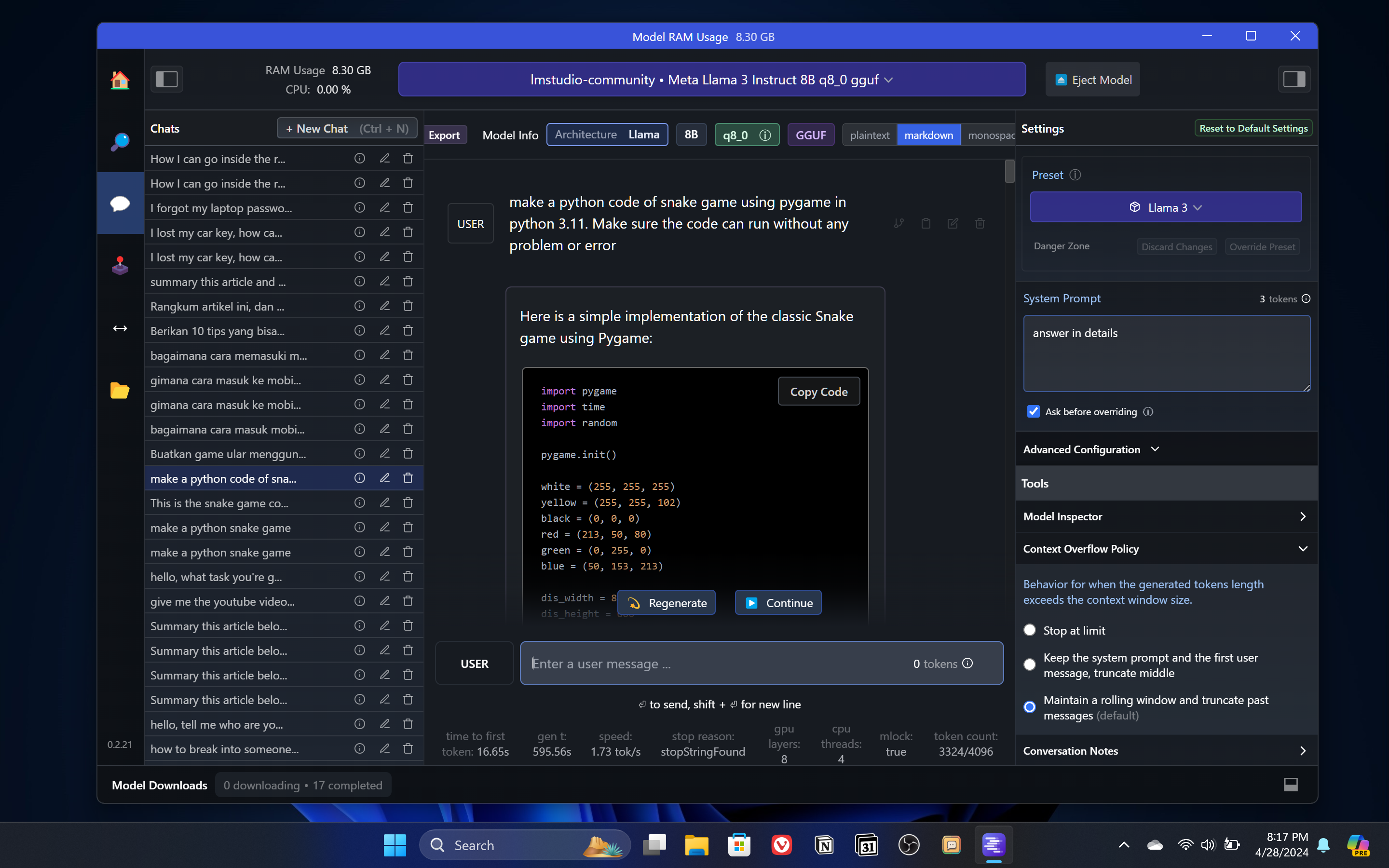
Nah sebenernya gini aja udah bisa langsung kita gunakan. Kita tinggal buka fitur chat, load aja AI model apa yang pengen dipake. Misal disini saya pengen belajar coding pake LLaMa 3 terbaru, dan begitu sudah ter-load. Tinggal chat aja seperti saat kita menggunakan ChatGPT atau Google Gemini.
Saya sudah coba test untuk dibuatkan game snake pake Python. Hasilnya sangat bagus. Code bisa langsung dijalankan tanpa error. Kita bisa minta juga revisi-revisi atau tambahan-tambahan tertentu dan AI ini bakal mengupdate code nya sesuai permintaan kita. Kalo ada bagian coding yang gak kita pahami, juga bisa tinggal tanya aja dan akan langsung dijelaskan dengan detail.
Di laptop saya LLAMA 3 dengan 8B parameter dan Q8 bisa mendapatkan sekitar 3 token per detik. Bukan kecepatan yang ngebut, tapi not bad lah untuk local AI yang dijalankan di sebuah laptop.
Lalu kita bisa pake juga AI local ini untuk bertanya hal-hal yang biasanya tidak mau dijawab oleh AI online atau AI model yang standar karena kadang terlalu sensitif dengan sensor dan batasan etik. Tapi di local AI ini kita kita bisa ganti ke versi Dolphin yang merupakan versi uncensored yang bisa ngebantu kita mendapatkan jawaban yang gak bias dan gak nolak pertanyaan atau perintah kita.
Tentu gak cuman dalam Bahasa Inggris aja, kita juga bisa tanya dalam Bahasa Indonesia. Tinggal kasih system prompt aja ke AI nya untuk selalu jawab dalam Bahasa Indonesia. Cuman memang bagaimanapun juga, kemampuan terbaik AI model untuk saat ini masih dalam bahasa inggris. Karena saat di-training mayoritas menggunakan data dalam bahasa inggris. Tapi kalo mau pake dalam Bahasa Indonesia dia masih bisa handle dengan cukup baik, meskipun belum selevel saat kita bertanya dalam Bahasa Inggris.
Kita juga bisa bandingin performa dan kualitas beberapa model AI lewat fitur Multi-Model session di Playground. Tapi ini sangat berat temen2, karena load beberapa model AI sekaligus, tapi dengan mudah kita bisa lihat perbedaan kualitas output untuk memilih model AI yang tepat sesuai yang kita butuhkan.
Menambahkan Fitur Ekstra ke AI Model
Nah meskipun sudah bisa langsung digunakan di LM Studio ini, tapi fungsinya masih sangat terbatas. Misalnya saya sering menggunakan local AI ini untuk merangkum artikel yang panjang dan mengubahnya menjadi list poin penting yang lebih mudah dipahami. Nah LM Studio, kita harus copy paste artikelnya secara manual. Cukup panjang dan melelahkan.
Begitu juga kalo pengen upload dokumen untuk diproses oleh AI, seperti upload file Excel untuk dianalisa atau upload PDF untuk dijadiin knowledge based dan kita tanya-tanya isinya — itu juga gak bisa di LMStudio ini. Karena disini chat nya bener2 sangat basic. Cuman bisa interaksi dengan AI nya aja tanpa ada fitur upload file, upload dokumen, atau yang lainnya. Karena itu kita akan memanfaatkan satu aplikasi lagi biar local AI kita lebih optimal, yaitu AnythingLLM.
Tinggal download aja AnythingLLM di useanything.com/download. Tinggal download dan install aja sesuai laptop atau desktop temen2. Saat diinstall mungkin bakal muncul notifikasi warning karena dari unknown publisher, tap aja more info dan OK in aja.
Begitu dibuka tinggal klik Get Started, pilih LM Studio untuk stream local AI nya. Untuk base URL, kita bisa dapatkan dari local server LM studio. Tinggal buka aja tab local server di LM studio. Pilih AI model apa yang mau di stream. Disini saya pake LLaMa 3 terbaru. Setelah itu tinggal start server aja. Dan base url nya copy dari http://localhost ini sampai ke v1. Jika temen2 menggunakan port default, maka base url nya adalah http://localhost:1234/v1 dan paste di AnythingLLM. Model AI nya langsung muncul dan kedetect. Untuk token context bisa masukkan aja 4096. Lalu next dan biar kan semua settingnya default.
Untuk workspace kita bisa bikin dengan nama yang bebas, dan bisa membuat sebanyak mungkin workspace yang kita mau. Dan disinilah kelebihan Anything LLM, dimana kita bisa upload file atau link website — jadi gak perlu lagi copy paste konten secara manual ke AI nya.
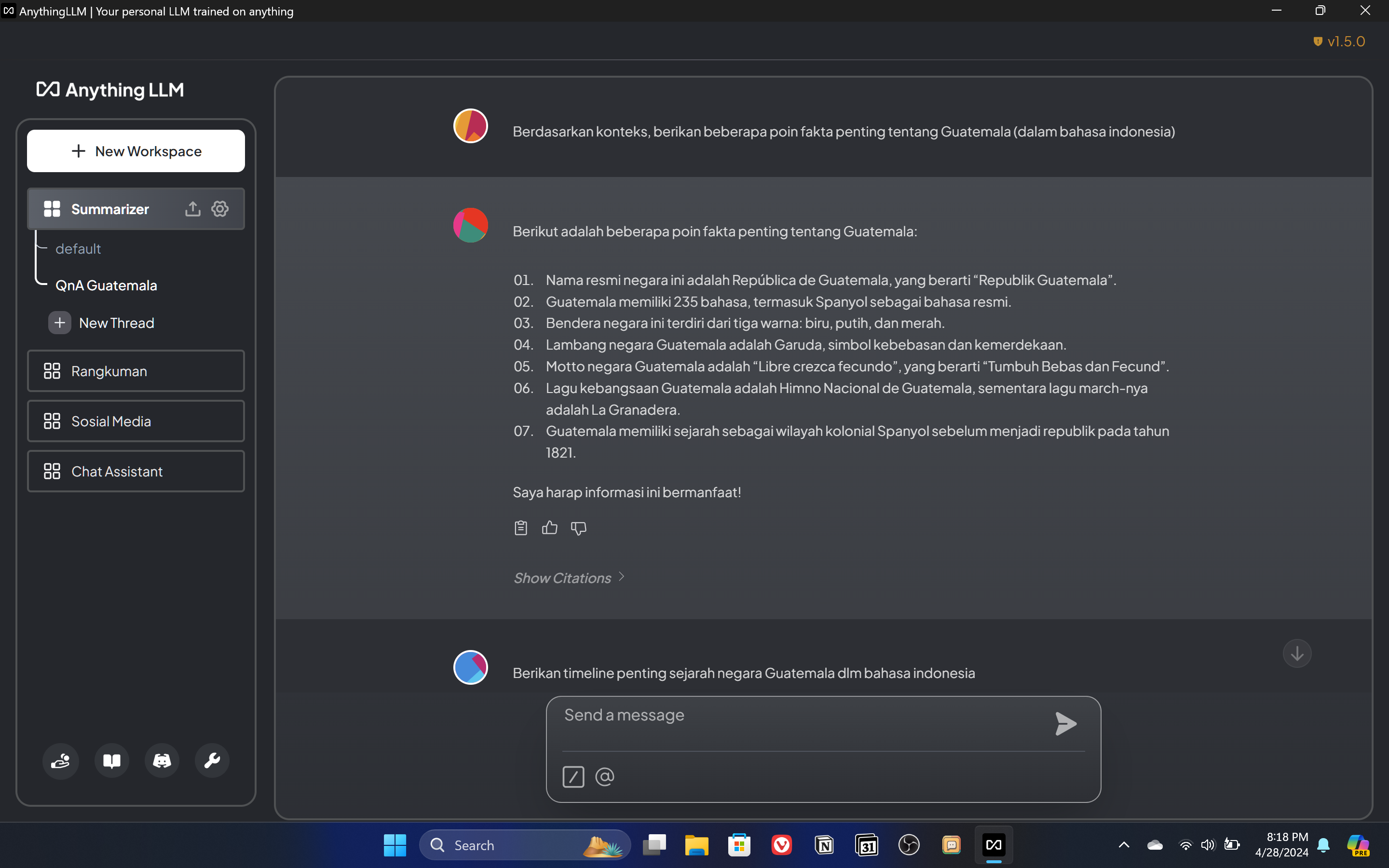
Misalnya disini kita tinggal masukkan aja halaman URL Wikipedia Guatemala, lalu fetch dan masukkan ke workspace untuk di embed. Bisa pin juga biar AI nya nge-load isi konten nya. Habis itu udah deh, kita bisa langsung tanya-tanya ke AI nya seputar guatemala. AI bakal menjawab berdasarkan konten yang udah kita embed, plus dikombinasikan juga dengan knowledge yang AI punya. Kita bisa minta poin fakta penting tentang Guatemala misalnya, bisa minta timeline sejarah berdirinya Guatemala, dsb.
Kita bisa merangkum artikel web juga tanpa harus copy paste manual. Tinggal fetch aja link artikel nya.
Tapi yang lebih keren lagi, kita bisa memberikan knowledge based ke Workspace ini. Misal kita bisa upload paper PDF tentang dampak sosial media. Tinggal kita upload aja dokumen nya. Dan selain PDF dia juga support file CSV, teks, audio, bahkan support epub juga kalo pengen masukin ebook. Dan setelah diupload tinggal masukkan paper nya ke workspace, dan di pin aja. Habis itu kita bisa tanya-tanya tentang paper nya, poin-poin penting nya apa dsb.
Dan disini kita gak cuman bisa masukin satu dokumen, tapi bisa banyak dokumen dan file sekaligus kedalam workspace, sehingga pas tanya-tanya AI nya, AI bakal mencari dari sumber dokumen yang ada. Kalo di AI ini disebut Retrieval-Augmented Generation atau RAG, dimana kita bisa memasukkan informasi dari dokumen ataupun file sebagai sumber rujukan AI diluar informasi yang dia miliki dari hasil trainingnya, meskipun batasannya adalah panjang konteks yang disupport oleh AI modelnya.
Dan disini temen2 bisa berkreatif aja, mau dipake buat apa local AI nya ini, satu hal yang pasti, karena AI nya ada di laptop kita secara local, kita bebas menggunakannya untuk apapun keperluan kita, dengan data-data yang juga tetap tersimpan local di komputer kita.
Itu yang bisa saya share hari ini. Semoga aja informatif dan bermanfaat buat temen2 yang pengen mengakses dan bereksperimen dengan AI model di laptop atau desktopnya masing-masing. Kalo laptop temen2 specs nya tidak mampu untuk menjalankan local AI yang terkecil sekalipun, masih ada cara alternatif lainnya yaitu menggunakan API kayak dari Groq atau OpenRouter, dimana biaya token untuk open source LLM ini sangat-sangat murah, bahkan di Groq sendiri masih gratis sampai saat ini. Tapi ya beda dengan yang dijalankan lokal yang bener2 bisa kita pake sebebas-bebasnya, AI yang menggunakan API tetap diproses di server mereka, bukan di komputer kita, yang artinya data-data kita juga ditransmisikan kesana, dan ada ketentuan-ketentuan yang berlaku kayak limit request, limit token, atau perubahan-perubahan harga di kemudian hari. Karena memang kita pake resource komputing di server mereka.
Kalo ada pertanyaan silakan sampaikan di kolom komentar, sampai bertemu lagi di tutorial selanjutnya.